
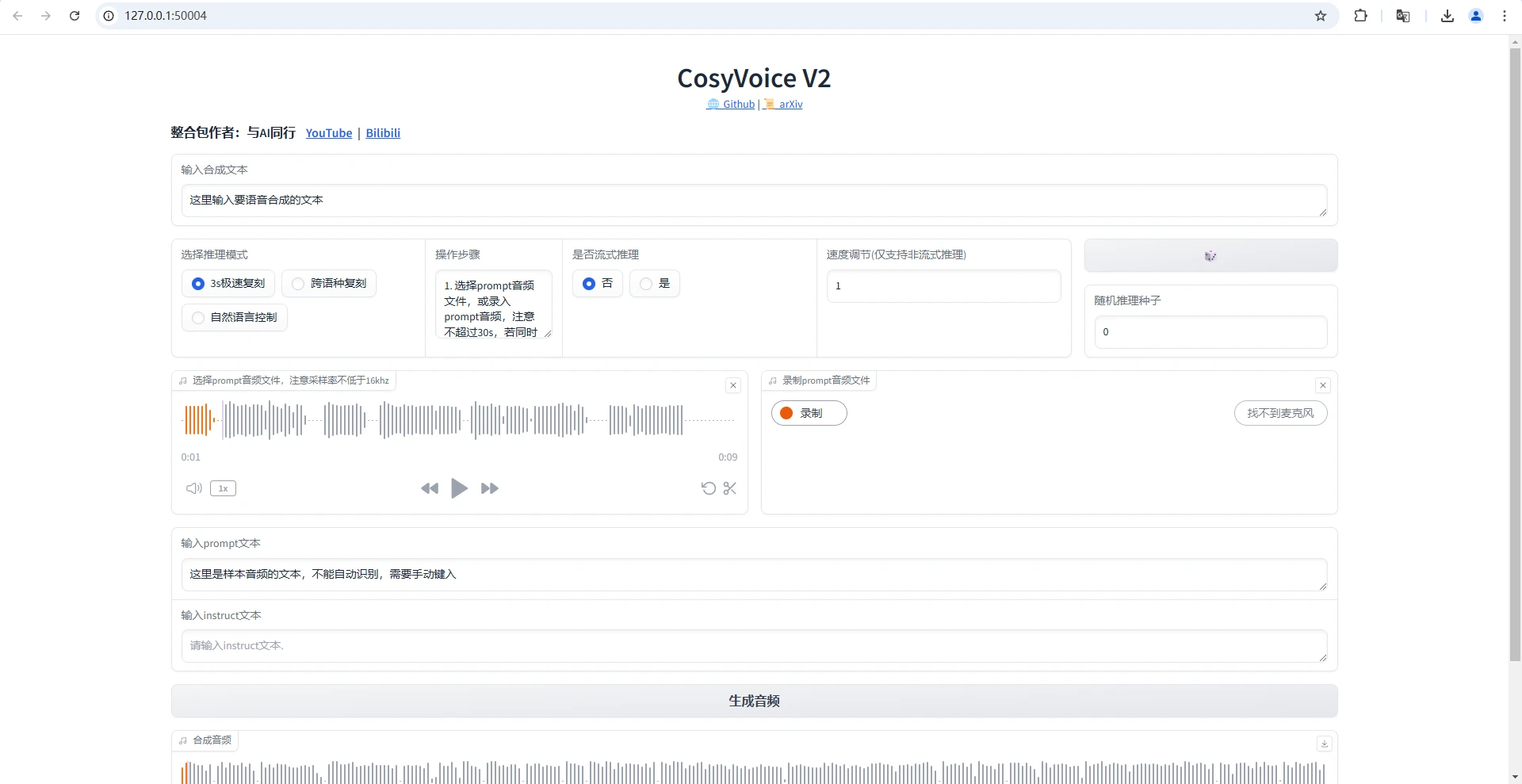
CosyVoice是阿里通义实验室推出的免费开源的语音生成大模型。它是基于之前版本改进的可扩展流式语音合成模型,引入了有限标量量化,简化了文本到语音的语言模型架构,并设计了分块因果流匹配模型。
具有超低延迟,首次包合成延迟可达 150ms;高准确性,相比 V1.0 发音错误减少 30%-50%;强稳定性,零样本和跨语言语音合成音色一致;自然体验佳,MOS 评分达 5.53,还支持更细粒度情感控制和方言口音调整等特点,支持中文、英语、日语、韩语及多种中国方言,可用于配音、语言学习、内容创作等领域。
经过站长测试,克隆生成出来的音频的效果还不错,不输市面上付费的AI声音克隆产品,下面是站长测试生成的一段语音。
值得注意的是,V2这个整合包并不包含保存已经克隆的角色模型,每次克隆都要上传对应的源音频片段,且还需要自己手动将源音频内的文本内容输入到prompt文本框内,才能进行生成。
优点是这个模型的整合包简单易用,且性能强大,配置要求不高,生成的音频效果很好。
缺点是这个模型整合包并不支持自动识别源音频内容,还不能保存已经克隆过的角色模型,每次克隆都要上传对应的角色源音频和手动输入源音频的文本内容才能生成,使用上比较麻烦。
V2这个模型的音频是通过分段生成,如果要生成的文本过长,那么系统便会将内容切片分块,一段一段合成,再把已生成的音频拼接并输出在试听区,生成过程中的音频可以随时试听,直到音频完全生成完毕,再点击试听右边的下载按钮就可以将生成的wav格式音频下载到本地使用了。
V3可以生成保存克隆角色并在下次生成语音时直接选择音频角色进行生成,不过V3的模型对于显卡性能要求是比较高的,推荐显卡显存不低于8GB。
下载注意:
本此的大模型整合包使用分片压缩,需要完整下载7z.001-7z.005的所有文件,且需要支持分片压缩的解压软件进行解压操作,解压软件可以在下面这篇文章内下载。
加载中...
下载全部文件后,请确认所有的文件放于同一目录下,使用支持分片压缩的解压软件打开CosyVoice_V2.7z.001文件,然后根据正常的解压操作进行解压即可,解压出来后双击运行“启动.exe”即可使用。
软件截图
下载地址
CosyVoice
来源:初春云盘
 桂ICP备2021008816号-2
桂ICP备2021008816号-2